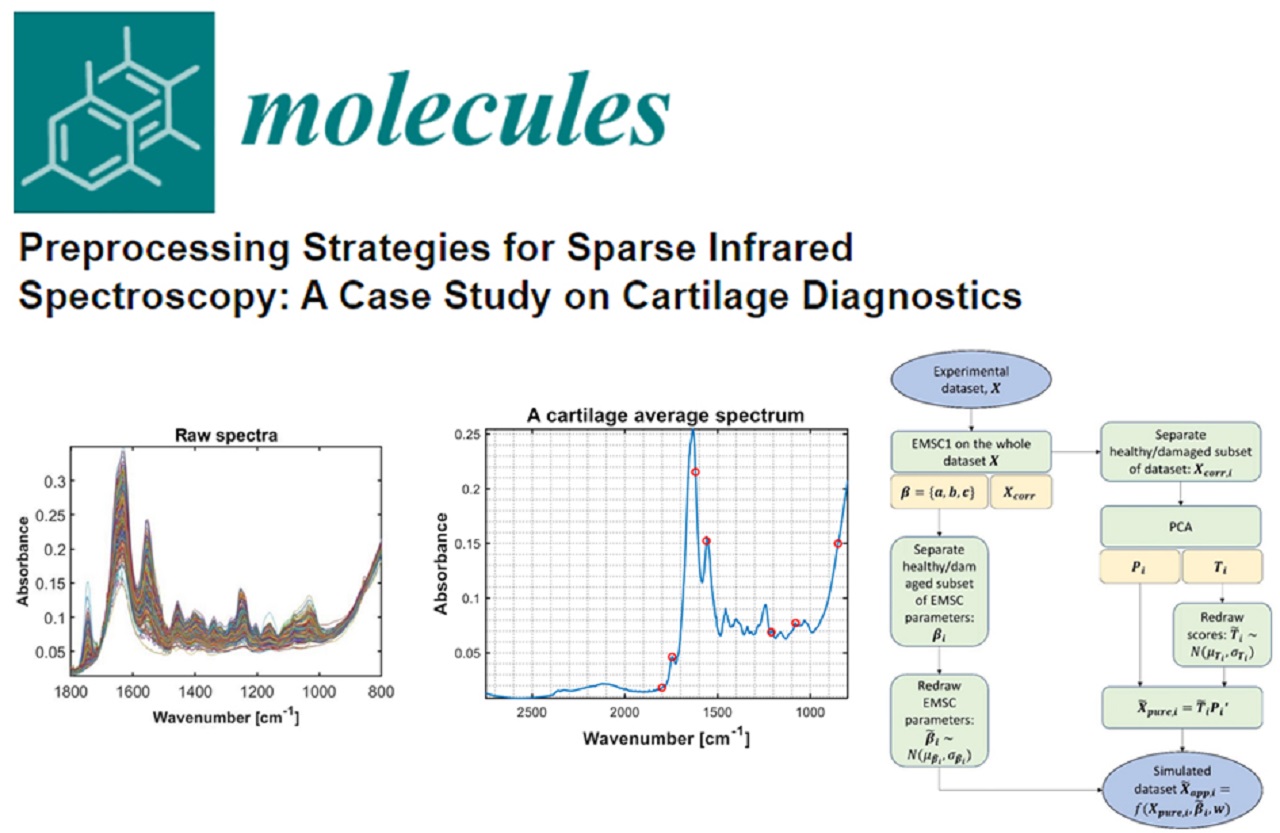
In order to provide timely evaluation of articular cartilage via spectroscopy measurements, the MIRACLE project will develop protocols for spectral preprocessing as well as the discrimination model based on spectral data. NMBU will develop and refine models for signal enhancement, scatter correction and spectral component selection for the data obtained with the developed MIR-ATR probe.
There are number of challenges related to development of the QCL-based MIR-ATR probe, one of them is component or variable selection to establish the calibration model. To make the probe feasible to use and to allow the precise identification of tissues, only a few variables should be identified.
Spectral fingerprints of biological samples are multivariate signals with highly collinear variables. To identify the most important spectral components, multivariate methods based on latent variables such as partial least-squares discriminant analysis (PLS-DA) can be used. PLS-DA allows direct interpretation of its results at biochemical level explaining the discrimination between different types of tissues through chemical composition. Variants of PLS-DA methods exist which provide powerful variable selection techniques.
NMBU mostly uses Sparse PLS-DA methods for variable selection which is based on imposing sparsity on the loading vectors in a PLS-DA model by setting a threshold parameter to penalize small loadings turning them to zero. This method works well for data where noise is lower than the signal as is the case for most of the data generated by the existing spectroscopic techniques.
Other methods such as artificial neural network (ANN), random forests, and support vector machines will be tested for the variable selection problem for QCL-based MIR-ATR probe. We expect to obtain more information by using multi-block methods where different data blocks (referring to different measurement methods that were applied to the same sample) can be integrated in one data model.